Linux系统与网络管理
Run LLM on your own machine.

基础知识速通
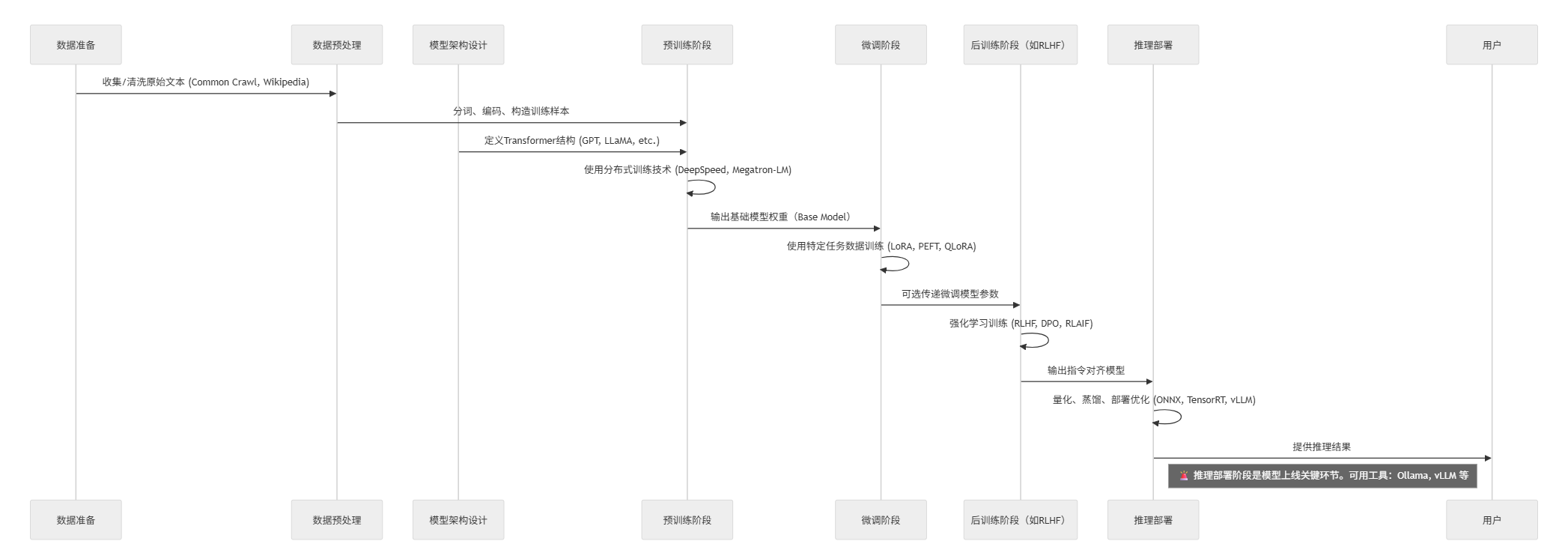
%%{init: {
'theme': 'neutral',
'mirrorActors': true
}}%%
sequenceDiagram
participant 数据 as 数据准备
participant 预处理 as 数据预处理
participant 模型架构 as 模型架构设计
participant 训练 as 预训练阶段
participant 微调 as 微调阶段
participant 后训练 as 后训练阶段(如RLHF)
participant 推理 as 推理部署
数据->>预处理: 收集/清洗原始文本 (Common Crawl, Wikipedia)
预处理->>训练: 分词、编码、构造训练样本
模型架构->>训练: 定义Transformer结构 (GPT, LLaMA, etc.)
训练->>训练: 使用分布式训练技术 (DeepSpeed, Megatron-LM)
训练->>微调: 输出基础模型权重(Base Model)
微调->>微调: 使用特定任务数据训练 (LoRA, PEFT, QLoRA)
微调->>后训练: 可选传递微调模型参数
后训练->>后训练: 强化学习训练 (RLHF, DPO, RLAIF)
后训练->>推理: 输出指令对齐模型
推理->>推理: 量化、蒸馏、部署优化 (ONNX, TensorRT, vLLM)
推理->>用户: 提供推理结果
note right of 推理: 🚨 推理部署阶段是模型上线关键环节。可用工具:Ollama, vLLM 等
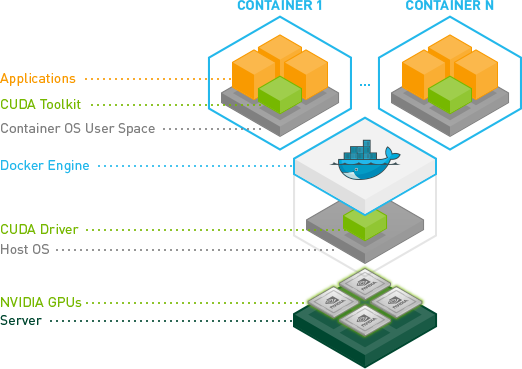
容器化 GPU 部署典型组件架构
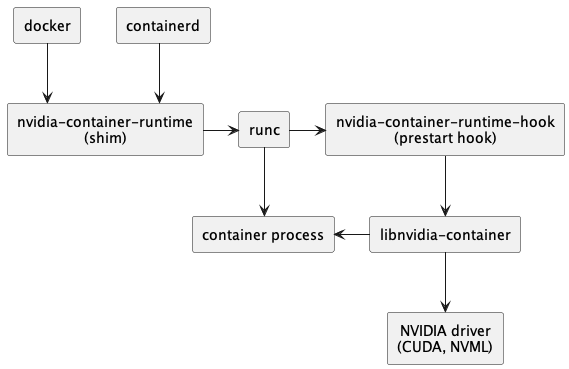
容器化 GPU 部署典型技术调用链
ollama + one-api + open-webui
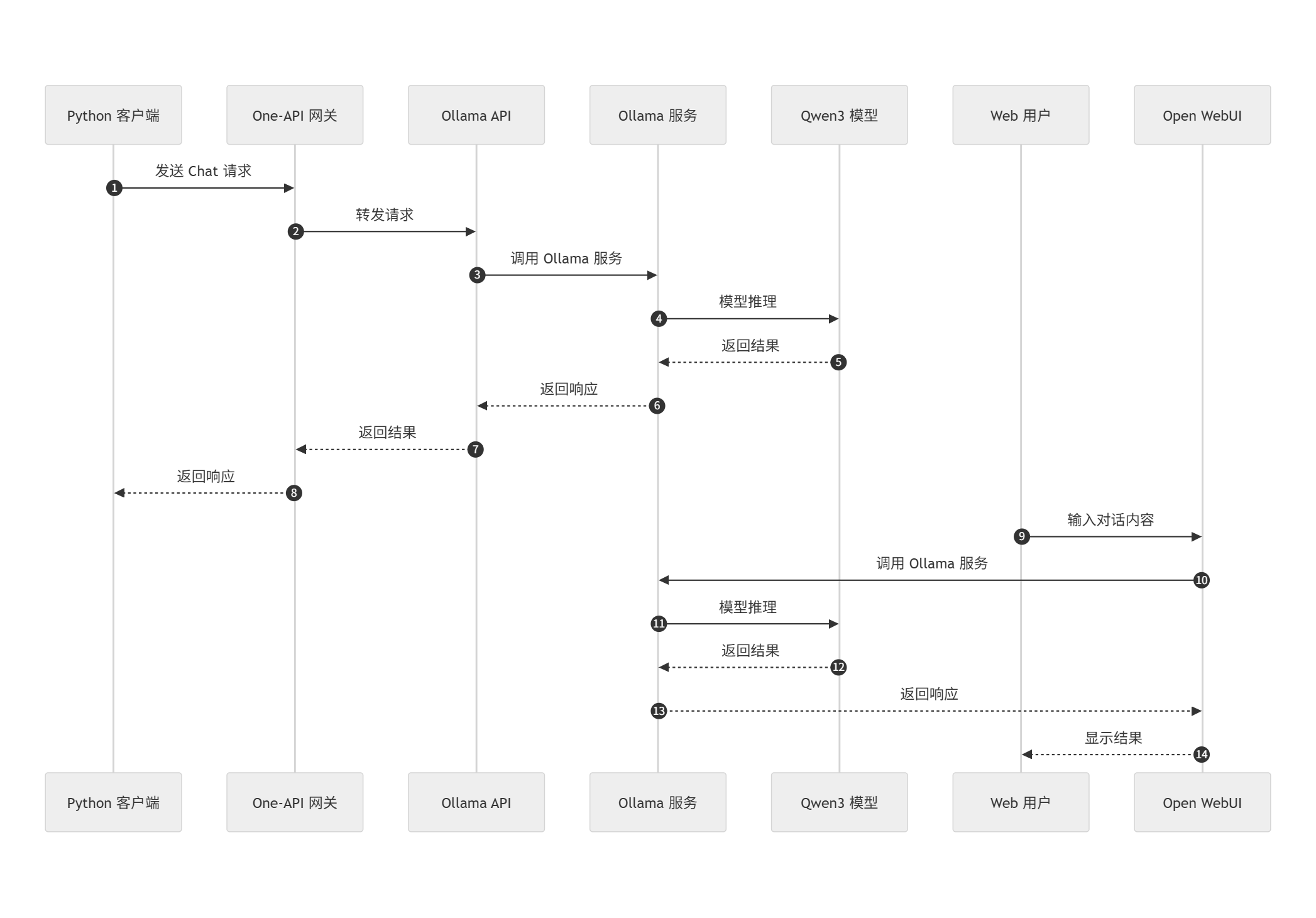
%%{init: {
'theme': 'neutral',
'mirrorActors': true
}}%%
sequenceDiagram
autonumber
participant PythonClient as Python 客户端
participant OneAPI as One-API 网关
participant OllamaAPI as Ollama API
participant OllamaSvc as Ollama 服务
participant Qwen3 as Qwen3 模型
participant WebUser as Web 用户
participant OpenWebUI as Open WebUI
%% Python 客户端流程
PythonClient->>OneAPI: 发送 Chat 请求
OneAPI->>OllamaAPI: 转发请求
OllamaAPI->>OllamaSvc: 调用 Ollama 服务
OllamaSvc->>Qwen3: 模型推理
Qwen3-->>OllamaSvc: 返回结果
OllamaSvc-->>OllamaAPI: 返回响应
OllamaAPI-->>OneAPI: 返回结果
OneAPI-->>PythonClient: 返回响应
%% Web 用户流程
WebUser->>OpenWebUI: 输入对话内容
OpenWebUI->>OllamaSvc: 调用 Ollama 服务
OllamaSvc->>Qwen3: 模型推理
Qwen3-->>OllamaSvc: 返回结果
OllamaSvc-->>OpenWebUI: 返回响应
OpenWebUI-->>WebUser: 显示结果